6 minutes
Kubernetes Falco
Descripcion
Preparacion de entorno de detección en la nube CDR (Cloud-Native Detection & Response). Utilizaremos la herramienta Falco en nuestro cluster de K8s con Kubeadm. Falco Es capaz de detectar comportamientos anomalos en los contenedores del cluster, gracias a él podremos tener un control y alertador de un cluster enrome, que de manera individual sería imposible monitorizar. Es imprescindible en un entorno de Kubernetes para un agente de ciberseguridad ya que alertará de todo e indicará detalladamente de los incidentes.
Requisitos
- Cluster de Kubernetes instalado con Kubeadm.
- HELM previamente instalado
Instalacion de Falco
Para la instalación utilizaremos el gestor de paquetes de Kubernetes “Helm” Lanzaremos el siguiente comando para agregar el repositorio de la herramienta Falco y actualizar las librerias
helm repo add falcosecurity https://falcosecurity.github.io/charts
helm repo update
Creacion de contenedores Falco
Con el siguiente comando instalaremos falco con los siguientes parametros.
helm install falco falcosecurity/falco \
--namespace falco \
--create-namespace \
--set driver.kind=modern_ebpf \
--set falcosidekick.enabled=true \
--set falcosidekick.webui.enabled=true \
--set collectors.kubernetes.enabled=true \
--set resources.requests.cpu=100m \
--set resources.requests.memory=512Mi \
--set resources.limits.cpu=500m \
--set resources.limits.memory=1Gi
Donde definimos la creación de un nuevo “namespace”, indicamos el driver de firewall ebpf que se va a utilizar, si hay webUI para la interfaz web, los recursos maximos que va a consumir y su recolección dentro del cluster.
En caso de que falle el contenedor o la creación diagnosticaremos el error con el siguiente comando
kubectl logs -n falco daemonset/falco -c falco-driver-loader
En algunas instalaciones faltan los headers del kernel de linux en los nodos, se instalarán con:
sudo apt install -y linux-headers-$(uname -r)
NOTA: anteriormente se utilizaba “–set driver.kind=ebpf”, esta configuración esta deprecated y actualmente se utiliza “modern_ebpf”. El kernel 6.12 de Debian 13 es demasiado reciente, no hay driver precompilado en los repos de Falco, modern_ebpf usa CO-RE (Compile Once - Run Everywhere) y no necesita el paquete headers.
Existen dos tipos vigilantes que podemos instalar en el cluster.
- kmod -> integro del kernel de linux escrito en C. (Se carga con insmod)
- eBPF -> programa que se carga en kernel, mas seguro y dinamico.
- Más seguro que kmod (el kernel verifica el código)
- No requiere módulo de kernel compilado aparte
- Se puede cargar/descargar sin reiniciar
Un posible error es la falta de Volumen Persistente.
Warning FailedScheduling 15m default-scheduler 0/3 nodes are available: pod has unbound immediate PersistentVolumeClaims. not found
Borraremos el despliegue StatefulSet
kubectl delete statefulset falco-falcosidekick-ui-redis -n falco
Actualizaremos el setup de Falco eliminando el volumen persistente (PV) de redis ya que solo necesitaremos falco para detectar los incidentes y enviaremos los datos a plataformas externas o los exportaremos a otros sistemas.
helm upgrade falco falcosecurity/falco \
--namespace falco \
--reuse-values \
--set falcosidekick.webui.redis.storageEnabled=false
Borraremos los pods antiguos para que se vuelvan a crear correctamente apuntando al nuevo Volumen
kubectl delete pod falco-falcosidekick-ui-848fb7b9-5hhvc falco-falcosidekick-ui-848fb7b9-nm429 -n falco
Una vez hayamos instalado los paquetes necesarios reiniciamos los pods de Falco a traves del daemonset.
kubectl rollout restart daemonset/falco -n falco
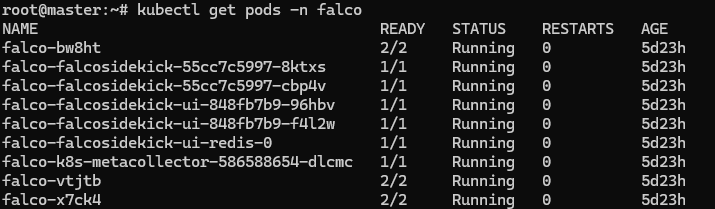
Monitoreamos la instalación:
kubectl get pods -n falco -o wide -w
Una vez esten todos en “Ready” procederemos a conectar la consola con “port-forward”.
kubectl port-forward svc/falco-falcosidekick-ui -n falco 2802:2802 --address 0.0.0.0
Accederemos al Dashboard con las credenciales “admin:admin” y accederemos a info para ver las caracteristicas de Falco. (Nota, cambiar la contraseña una vez estemos dentro)
Veremos que esta vacío asique vamos a generar una alerta para ver si se refleja en el panel. Crearemos un pod de nginx y lanzaremos el comando “cat /etc/shadow” para provocar una lectura de un archivo indebido como el usuario root.
kubectl run nginx --image=nginx
Una vez se haya creado y este en “Ready” nos conectaremos al pod y ejecutaremos el cat.
kubectl exec -it nginx -- /bin/bash
cat /etc/shadow
exit
Vamos a revisar el panel de falco.
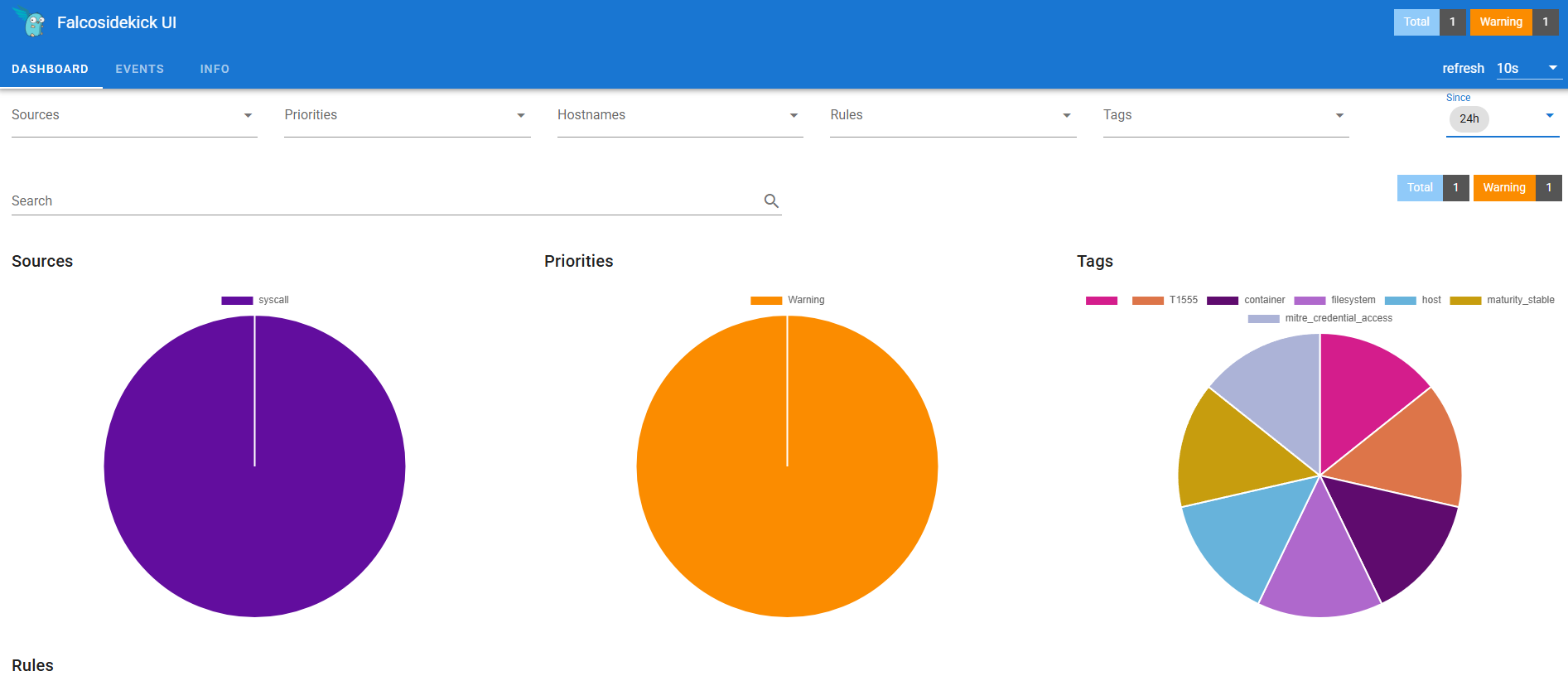
¡Bingo! en el dashboard principal ya nos indica detecciones, avanzaremos a la sección “Events” para ver mas detalles.
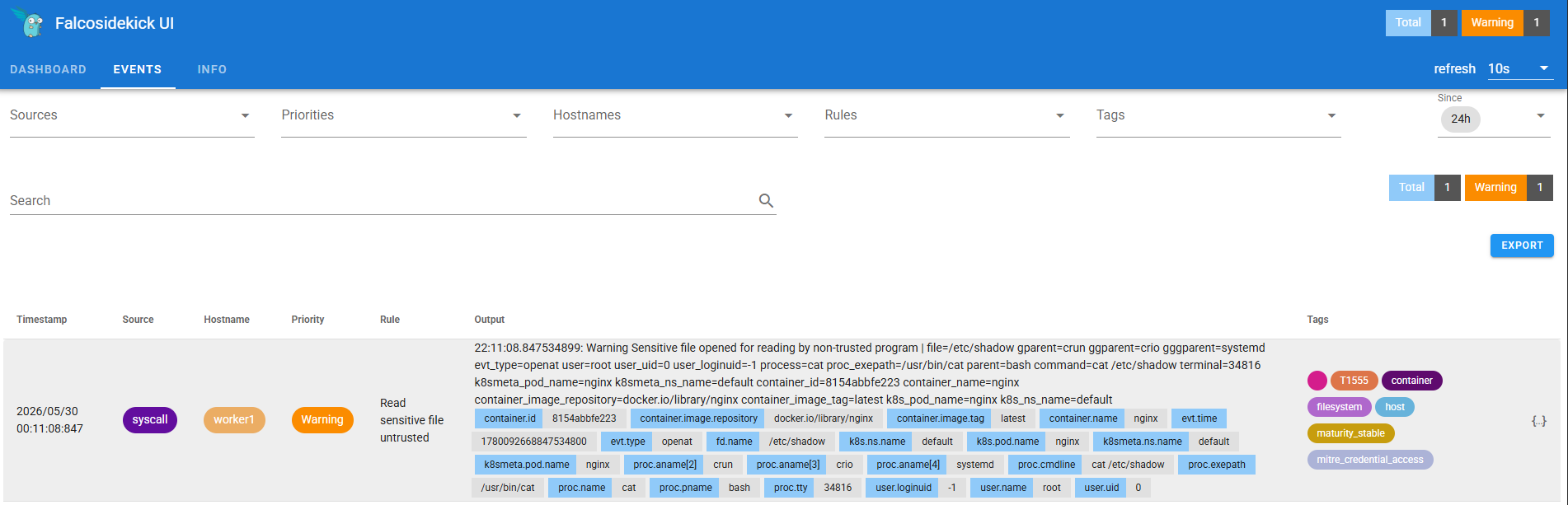
Podremos observar como se notifica la hora, el origen y el nodo trabajador desde el que se ha lanzado el comando. Tiene un indicador de prioridad y criticidad de las alertas junto a la regla que ha saltado. Veamos el Output:
22:11:08.847534899:
Warning Sensitive file opened for reading by non-trusted program
| file=/etc/shadow gparent=crun ggparent=crio gggparent=systemd
evt_type=openat user=root user_uid=0 user_loginuid=-1 process=cat
proc_exepath=/usr/bin/cat parent=bash command=cat /etc/shadow
terminal=34816 k8smeta_pod_name=nginx k8smeta_ns_name=default
container_id=8154abbfe223 container_name=nginx
container_image_repository=docker.io/library/nginx
container_image_tag=latest k8s_pod_name=nginx k8s_ns_name=default
Desglosando podemos destacar:
- El comando que se ha ejecutado
command=cat /etc/shadow - El proceso que ha lanzado la alerta con su path process=cat proc_exepath=/usr/bin/cat parent=bash
- La terminal desde la que se ha lanzado y su pod terminal=34816 k8smeta_pod_name=nginx
- La imagen de la que se ha obtenido ese pod el nombre y su version
container_image_repository=docker.io/library/nginx
container_image_tag=latest k8s_pod_name=nginx - El namespace en el que se encuentra
k8s_ns_name=default - Y el mensaje
Warning Sensitive file opened for reading by non-trusted program | file=/etc/shadow
Conexion a Grafana
Vamos a conectar Falco con Grafana. Para ello necesitaremos crear un “ServiceMonitor”. Ésto es un servicio íntegro que le indica a prometheus donde ir a buscar (scrapping) para indexar información en su base de datos que posteriormente pintaremos en Grafana.
Crearemos un archivo llamado “falco-servicemonitor.yaml” en el que indicaremos lo siguiente:
cat falco/falco-servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: falco-falcosidekick-monitor
namespace: monitoring
labels:
release: prometheus
annotations:
recordatorio-mental: "Este archivo vive en 'monitoring' pero vigila al namespace 'falco' para enviar las alertas a Grafana."
spec:
namespaceSelector:
matchNames:
- falco
selector:
matchLabels:
app.kubernetes.io/name: falcosidekick
app.kubernetes.io/component: core
endpoints:
- port: http
interval: 15s
path: /metrics
Este archivo crea un “ServiceMonitor” en el namespace monitoring con la etiqueta prometheus para que prometheus lo identifique. En las “spec” indicamos con matchNames y namespaceSelector a que namespace ir a buscar los pods para sacar la informacion, con “Selector” y matchLabels indicamos como se llaman los pods a escrapear y por último en endpoints indicaremos el puerto port http que viene definido por Kubernetes y el interval.
Nota: para averiguar el parametro port lanzaremos el siguiente comando
kubectl get svc falco-falcosidekick -n falco -o jsonpath='{.spec.ports[*].name}'
Nos indicará el nombre del puerto que utilzia el servicio de falco-sidekick, normalmente http y http-notls.
Aplicaremos el archivo con
kubectl apply -f falco-servicemonitor.yaml
Comprobamos que se ha creado correctamente.
kubectl get servicemonitor -n monitoring
Debería de aparecer una linea como “falco-falcosidekick-monitor”
Accederemos a prometheus y en la sección targets veremos el “ServiceMonitor” de Falco en estado UP
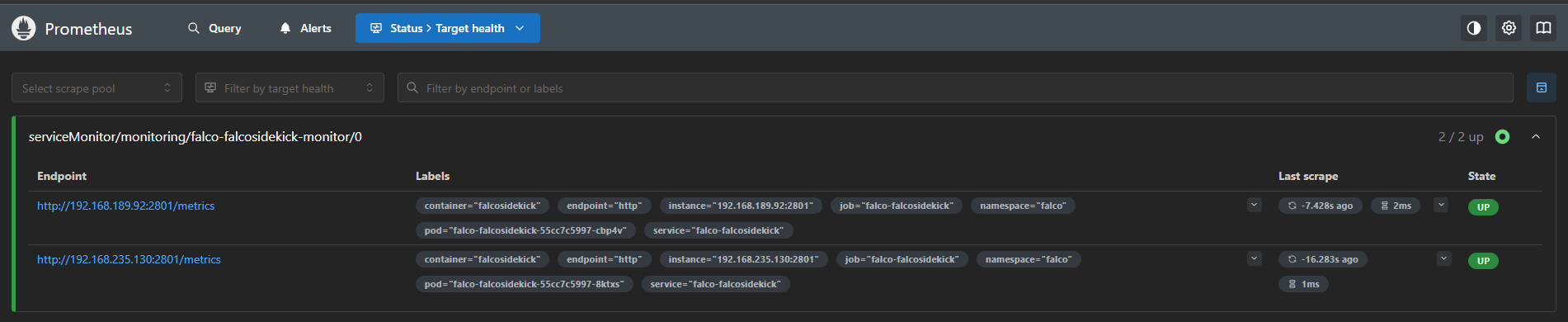
Crearemos un nuevo evento con el siguiente comando
kubectl exec -it -n falco $(kubectl get pods -n falco -l app.kubernetes.io/name=falco -o jsonpath='{.items[0].metadata.name}') -- cat /etc/shadow
Nos dirigiremos a Grafana y crearemos una nueva dashboard, creamos una nueva visualización e introducimos Prometheus como origen (source). Indicaremos en el apartado “Metric” el elemento que queramos de Falco (falcosecurity_falcosideckick_falco_envets_total) y veremos como el evento que hemos generado aparece.
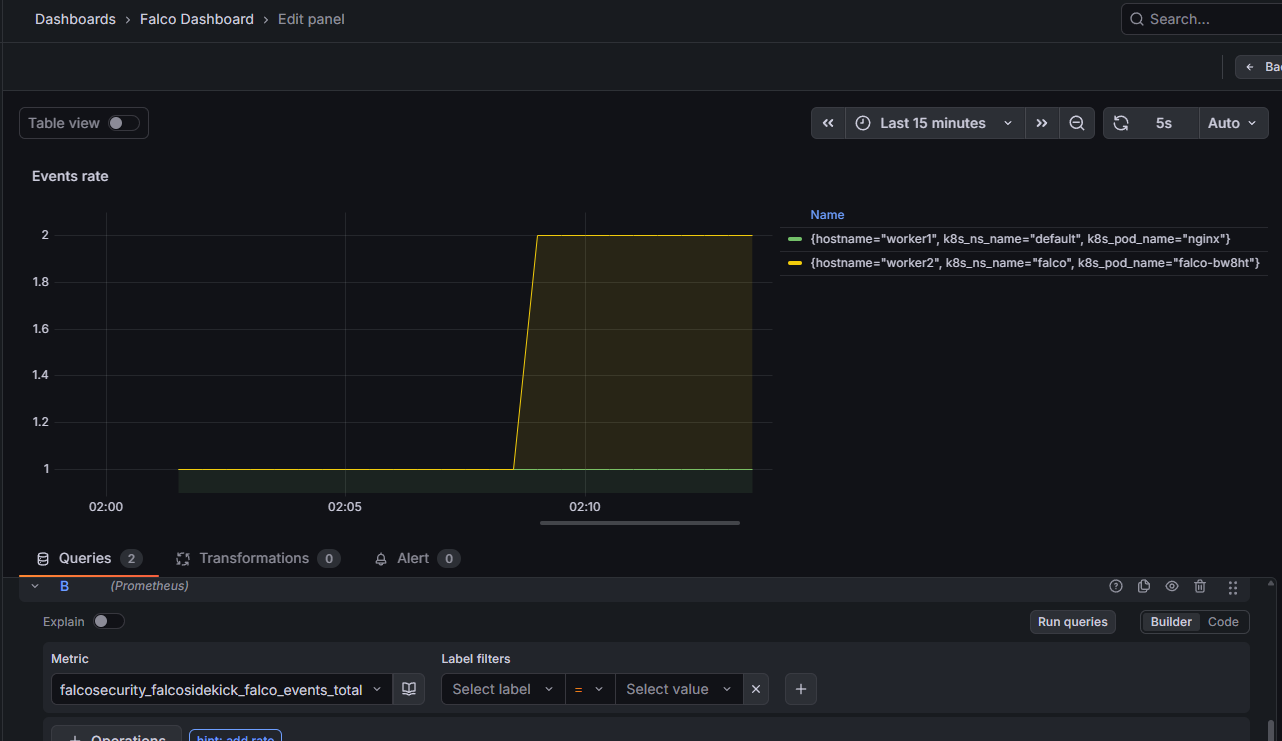
Conclusion
Como podemos ver tenemos una monitorización activa y completa de contenedores que incluso ¡¡SE ACABAN DE CREAR!!
Gracias a esta herramienta el control es absoluto, podremos copiar en formato json la alerta incluso para trasladarla a Grafana o ELK con el scraper de prometheus.
Esta monitorización es muy detallada y profunda, otorgando una gran cantidad de datos y tranquilidad a quien monitoriza un cluster.
Falco es una herramienta muy potente y a tener en cuenta en cualquier despliegue de kubernetes.